How We Made an AI Agent Remember: Memory Architecture That Survives the Context Window
A three-layer memory architecture for long-lived coding agents — a six-class governance taxonomy, a class-aware retrieval index, and a session-start priming hook — plus the resilience layer we didn't plan for.
A coding agent that doesn’t remember is a coding agent that re-learns the same lesson every Monday. We’ve spent the last several months building a memory layer for our agent harness — the system that survives session boundaries, ranks recall by relevance, and injects the right thing into model context before the user’s first prompt lands. This post is what we learned, generalized so any team running long-lived agents can pick up the pattern.
The thesis in one sentence: memory needs governance, retrieval needs ranking, and the harness needs a hook to inject the right thing at the right time. Three layers, each doing one job. We’ll walk through them in order.
The problem
Modern coding agents — Claude Code, Cursor, Copilot Workspace, homegrown LLM loops — share a structural weakness. Every session starts cold. The model doesn’t remember last week’s “don’t echo $SECRET” lesson, the project’s six naming conventions, or that one time the indexer silently dropped half its rows because someone set an environment variable on the wrong host.
The naïve fix is to dump everything into the system prompt. We tried that. Two things break. First, you burn tokens — every always-loaded byte costs something on every turn, every session, forever. Second, and worse, you degrade reasoning quality. Models attend less effectively as the prompt grows. A 40KB block of process docs at the top of the conversation can make the model less able to follow instructions further down.
Two failure modes kept showing up:
- The rediscovery loop: the agent solves the same problem from scratch, often slightly differently each time, because the lesson from the previous session wasn’t in context.
- The buried decision: the agent had access to the right information but couldn’t surface it. A short, dense lesson written last Tuesday was outranked by a verbose process doc that happened to share more keywords with the query.
Both problems are about what the model sees, not what’s on disk. Storage is cheap; attention is the budget. So the question becomes: how do you put the right 8KB in front of the model and leave the other 4MB available on demand?
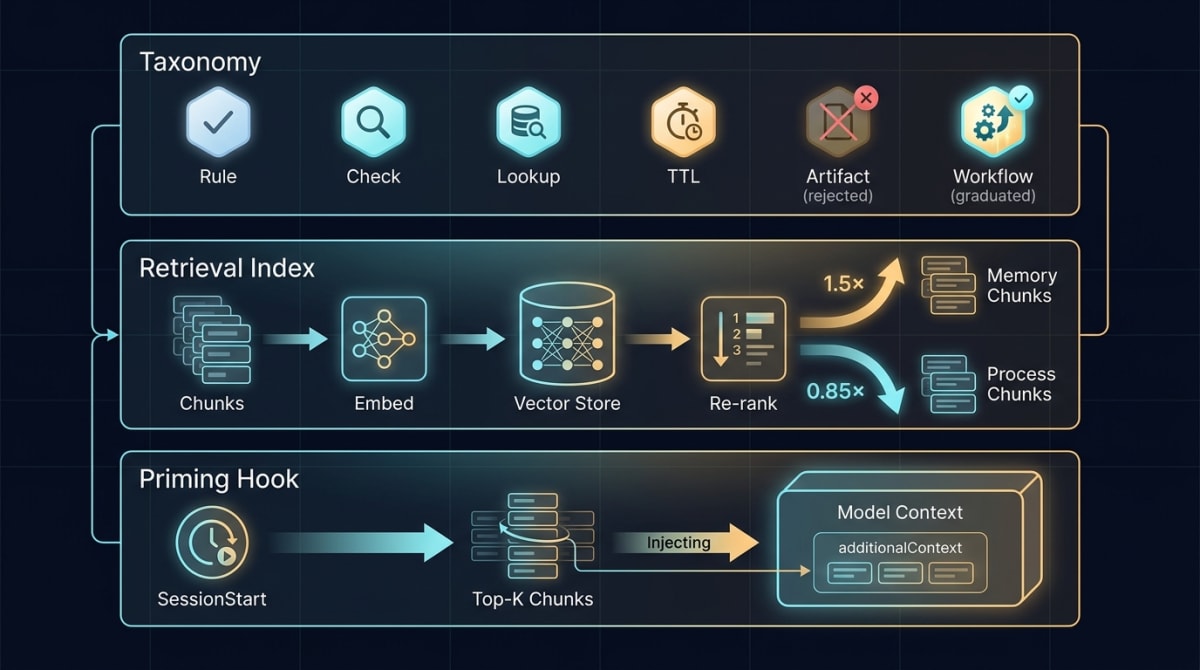
Layer 1 — A taxonomy for what to remember
Before retrieval, before ranking, before any vector math, you need a gate. Most of what passes through an agent session shouldn’t be remembered. The gate is a six-class taxonomy. Every candidate memory entry gets classified before it’s written.
- Durable preference / rule — applies to all sessions. “Plans live in this directory.” “Use this style of commit message.”
- Check-before-action rule — imperative, scoped to a class of work. “Never
echo $SECRET.” “Verify the branch after a stash pop.” - Lookup / reference — UUIDs, command signatures, paths, API call examples. Useful when needed, useless when always-loaded.
- Time-bounded state — sprint checkpoints, deadline-gated decisions, anything that expires. Tagged inline with a TTL (time-to-live, e.g.
TTL: 2026-05-15) and pruned automatically. - Historical artifact — DECLINE. “We shipped X on date Y” lives in
git logand the issue tracker. Re-encoding it in memory just creates a fossil that contradicts the source of truth as it drifts. - Workflow procedure — multi-step recipes the agent runs repeatedly. These graduate into a skill (or whatever your harness calls a procedure module) with trigger keywords, not into memory.
Routing logic falls out of the classes. (1) and (2) live in an always-loaded index file. (3) lives in a sibling topic file under a project-scoped memory directory, retrievable on demand. (4) lives in the index with the TTL inline. (5) and (6) get rejected at the gate.
The trick that makes this work is the index is not the content. We call ours MEMORY.md, but the name doesn’t matter. What matters is the structure: each entry is one line — - [Short title](topic_file.md) — one-sentence hook. The hook teaches the model when to retrieve. The body lives in a separate topic file with YAML frontmatter (name, description, type, optional origin metadata) and gets loaded only when the model decides it needs the detail.
There’s also a negative-space rule, equally important: what we never store.
Don’t memorize: source code, raw git history, ephemeral diffs, build artifacts,
.envcontents, “we did X today” status updates. Memory is sculpted. Every entry should prevent a future reversion. If removing the entry wouldn’t make the agent measurably worse, don’t write it.
Why six classes and not three? Collapsing “lookup” with “rule” produces an index that grows without bound, because every API signature wants to be remembered. Collapsing “TTL state” with “rule” produces fossils — yesterday’s deadline is today’s confusion. Each class has a different eviction policy, and that’s what really matters. Storage decisions and retrieval decisions follow from the eviction model.
The taxonomy is governance. It’s the boring part. Without it, the index bloats, the always-loaded token cost climbs, and recall quality degrades because the signal-to-noise ratio drops. Our first pass had no governance — anyone could append. We hit 18KB in the always-loaded file before the per-session token cost started showing up in the budget. The six-class retrofit was painful. Build the gate first.
Layer 2 — A retrieval index that respects class
The taxonomy decides what gets stored. The retrieval index decides what gets surfaced. This is the densest layer.
The stack, by job (so you can swap any piece for a near-equivalent):
- On-disk vector store —
@ruvector/core. Native bindings, cosine distance, comfortably handles tens of thousands of chunks on a developer laptop. Pinecone, LanceDB, orpgvectorwould work too. - Embeddings —
all-MiniLM-L6-v2. 384-dimensional, runs on CPU in single-digit milliseconds, “good enough” for ranking lessons. We tried larger models; the marginal recall gain didn’t justify the latency. - Tool exposure —
@modelcontextprotocol/sdk. Surfaces the index as Model Context Protocol (MCP) tools (<prefix>_search,<prefix>_status,<prefix>_reindex; we ship asskill_docs_*) so the agent queries memory the same way it calls anything else. - Telemetry —
better-sqlite3. A separate database for retrieval-event logging, capture-rate measurement, and outage detection. We’ll come back to it in Layer 4.
Write path
Source adapters per content type — memory topic files, retrospective notes, design docs, script header comments, pull-request bodies. Each adapter labels its chunks with a class array (["memory"], ["process-doc"], ["script-header"]) so the re-ranker has something to work with later.
Chunking parameters that worked for us: 240-token target with 48-token overlap, 32-token minimum. Files smaller than the target emit one whole-file chunk — cleaner than synthetic splits. We cap embedding input at 1000 characters before passing it to the model; the model itself would otherwise truncate at 256 tokens, but doing it ourselves at a fixed byte count keeps chunk boundaries reproducible across runs.
Memory topic-file paths get encoded as memory://<user>/<basename> URIs before storage. This keeps absolute home paths out of the persisted metadata. A future-you investigating a corrupted index doesn’t want to grep through /Users/yourname/... in the metadata.
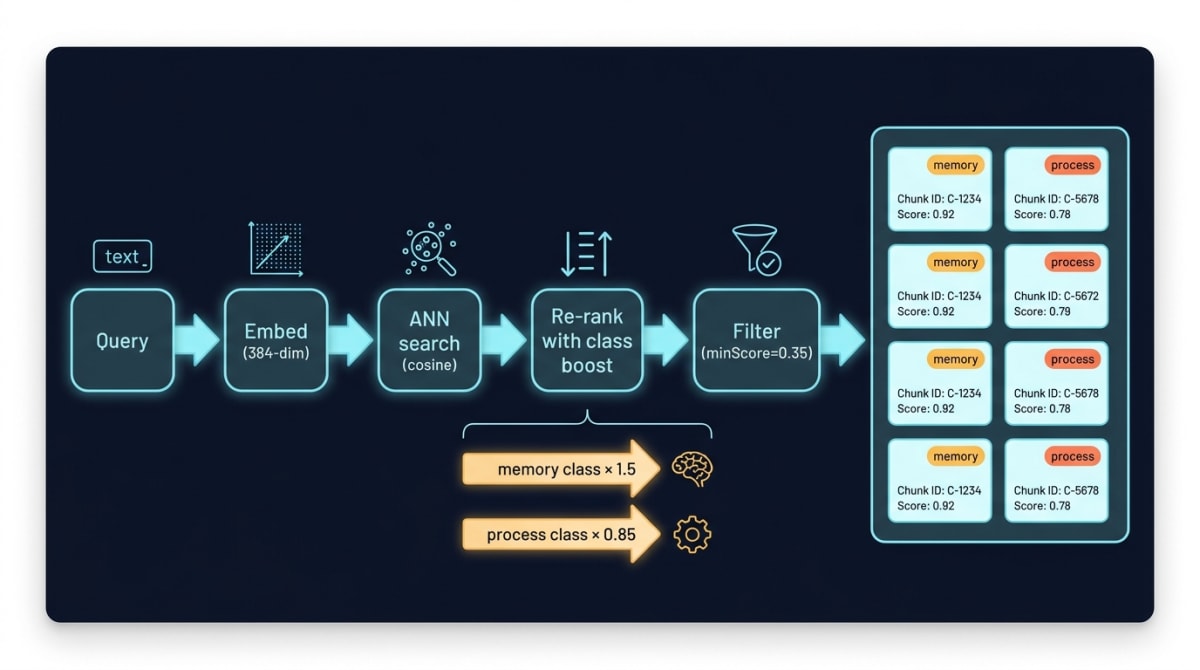
Recall path
Query → embed → db.search({ vector, k }) returns cosine distance in the range [0, 2]. Convert to similarity in [0, 1] using max(0, min(1, 1 - distance/2)). Apply the minimum-score floor (0.35 for us) after re-ranking, not before — this matters, and it’s the inverse of what most tutorials show.
The re-ranking trick
Pure cosine ranking has a structural bias. Verbose process documentation generates more high-similarity chunks than a single tightly-written lesson, simply because it covers more surface area. A four-line “don’t echo secrets” lesson loses to a 40KB style guide that mentions secrets in passing. The model gets the wrong context.
The fix is class-aware multipliers, applied to similarity before any penalties (simplified for the post — the production version reads class strings off chunk.meta.class and clamps the env-supplied factors to safe bounds):
function classBoostFactor(classes: string[]): number {
if (classes.includes('memory')) return 1.5; // boost
if (classes.includes('process-doc')) return 0.85; // dampen
return 1.0;
}
const boostedScore = rawSimilarity * classBoostFactor(chunk.classes);Memory chunks (the lessons we deliberately wrote down) get 1.5×. Process docs (verbose by necessity) get 0.85×. Everything else stays at 1.0×. The numbers came from tuning over a few weeks of recall logs. They’re not magic; they’re the operating point we landed on.
Falsifiable, not folklore. Tuning constants without a measurement loop becomes a religion. We added a 55-entry gold set across six query categories (memory recall, retro lookup, implementation lookup, script-header lookup, ADR lookup, skill discovery) and a CI gate that computes recall@5, recall@10, MRR, and nDCG@10 on every PR that touches the boost/dampen/floor constants. The gate fails if recall@5 drops more than 5% versus the prior committed baseline. Ablation runs sweep one dimension at a time (boost, dampen, floor, BM25 on/off) and emit a signed-delta table in markdown or JSON. The harness lives in
packages/doc-retrieval-mcp/eval/— gold-set design, metric implementations, ablation runner — alongside a baseline-drift check that blocks any ranking-code PR shipping without an updated baseline. If you keep1.5and0.85as constants, keep them honest.
(The class strings 'memory' and 'process-doc' above are generic placeholders; the actual labels are stamped per source adapter. In our deployment they’re feedback/project for memory topic-files and wave-spec/plans-review for process docs — different adapters, different vocabularies, same boost/dampen structure.)
Two more penalties run after the boost:
- Absorption: a chunk marked
absorbed_by(replaced by a newer canonical version) drops tomin(score × 0.5, 0.5). The cap matters — it prevents a high-similarity-but-absorbed chunk from being completely evicted, just downgraded below the canonical artifact. - Supersession: a chunk marked
supersedes(older lesson explicitly replaced by a newer one) gets a flat× 0.5with no floor cap. If the newer version is in the index, it outranks.
The 0.35 floor applies last. This ordering is deliberate: it lets the class boost protect a relevant absorbed chunk against eviction, while keeping low-similarity noise out.
For belt-and-suspenders, you can run a Phase-2 pass over the top-K pool that blends embedding similarity with BM25 (a classic lexical-relevance score that rewards rare-keyword matches the embedding model averages away) and a maximum-marginal-relevance step for diversity — 60/40 embedding-vs-lexical weighting, MMR diversity weight (lambda) 0.5. We default it off. It helps for short factoid queries (“what UUID?”) and hurts for “find the lesson about X” queries, which are the bulk of agent traffic.
The MCP search tool itself defaults to top-K of 5; the priming hook in the next section pulls 8. Both are knobs.
Tunable everything
The boost (1.5), dampen (0.85), floor (0.35), and BM25 toggle are all environment variables, clamped to safe ranges, read at runtime. We can A/B these in production without a rebuild, observe recall logs, and revert by unset. This generalizes:
Infrastructure should not force policy decisions at code-review time. Engineers build mechanism. Operators tune. Data informs. Make every threshold a knob, default it sensibly, and document the knob. Future-you wants to A/B the boost factor at 2 a.m. without filing a PR.
Layer 3 — Session-start priming
The retrieval index is plumbing. Until something queries it at the right moment, the model never sees a single chunk. That moment is before the user’s first prompt arrives.
Most modern agent harnesses expose a SessionStart hook. Claude Code calls the injection point additionalContext; other harnesses with extension points — Cursor’s MCP and rules layer, hosted IDE plugins, custom LLM loops — expose analogous mechanisms by different names. The pattern is the same: a JSON payload returned by a hook gets prepended to model context before the conversation begins.
Our priming script does three things:
- Build a query by concatenating three signals:
- Branch name — we extract issue markers like
feature-1234. - Recent index entries — the last 15 bullets from a
## Recentsection pinned at the bottom of the Layer 1 index file, capped at 2KB. The## Recentsection is itself a structural convention worth adopting: append new entries there, and the priming hook auto-surfaces them while older entries fall out by recency. - Issue body — when the branch name resolves to an issue tracker entry, we fetch the body via API (with a short timeout and a fail-soft empty-string fallback).
- Branch name — we extract issue markers like
- Run the query against the retrieval index and take the top 8 chunks.
- Emit
additionalContextas JSON, also writing a transient mirror file for inspection (/tmp/session-priming-${SESSION_ID}.md, mode0600, swept after 24 hours).
Trigger conditions are narrow on purpose. We fire only on source=startup and only on branches matching the working-pattern. Idempotency window of 60 seconds prevents thrash on rapid restarts. On any other branch (main, off-pattern), the hook returns empty context — the agent is on a routine task, no priming needed.
The output looks roughly like this:
{
"additionalContext": "## Recently relevant\n\n- Lesson: don't echo secrets...\n- Pattern: branch verification after stash pop...\n- Reference: indexer schema..."
}The escape hatch matters as much as the feature. A single environment variable returns empty context — ours is SKILLSMITH_DOC_RETRIEVAL_DISABLE_PRIMING=1 (the prefix is project-specific; pick whatever your harness convention dictates). Use it for staged rollout, debugging, and — most importantly — benchmarking baseline-vs-primed agent quality. You can’t tell whether priming helps if you can’t turn it off.
Layer 4 (we didn’t plan for this) — Resilience
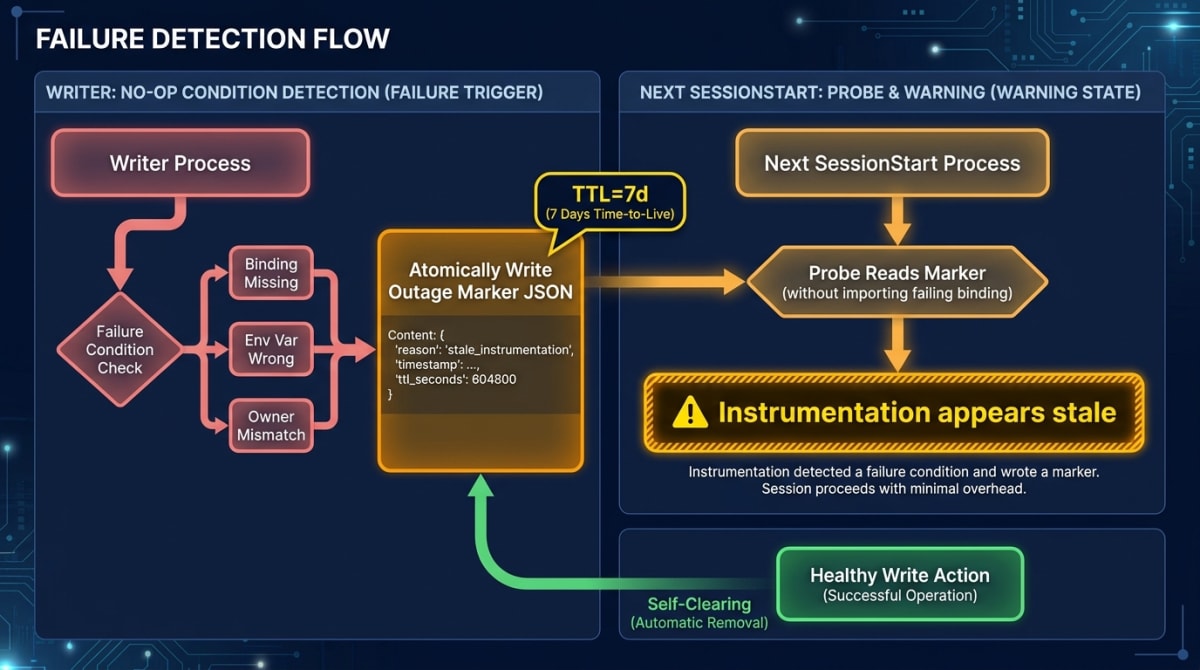
Priming is what should happen at session start. Layer 4 is what happens when the writer feeding the index has silently died and priming is now hallucinating freshness from a frozen snapshot. This is the section we didn’t plan to write. The pathology is universal: the writer no-ops silently. Could be a missing native binding, an environment variable set wrong, a permissions issue, a host/container boundary mismatch where one shell inherited a flag from another. Symptom: zero rows, no banner, days of debugging that should have been minutes.
The fix is a pattern, not a feature. When the writer enters a user-actionable no-op branch (binding load failure, owner mismatch, environment trap — but not the documented “I don’t write here” mode like inside a container that has its own writer), it atomically writes an outage marker JSON: path, reason, hint, owner stamp, timestamp.
On the next session start, a probe reads the marker. The probe is engineered specifically for this case: it never imports the broken binding at module top level, so a binding failure can’t crash the hook itself. (Don’t laugh — we made this mistake. The probe died on import, leaving no banner, leaving the user with no signal.)
If the marker is present and within its TTL (we use 7 days), the probe emits a banner into additionalContext:
**Warning — instrumentation appears stale.**
Reason: native binding failed to load
Hint: run `./scripts/repair-host-native-deps.sh`The marker self-clears on the next healthy write. There’s also a stand-alone probe script for ops monitoring — exit 0 healthy, 1 stale, 2 probe-failed. Wire it to your alerting.
Health verdicts we’ve found useful:
healthyoutage_marker_present(writer flagged itself)IS_DOCKER_set_on_host(the host/container boundary trap —IS_DOCKER=trueleaked from a sourced env file into a host shell, writer no-ops because it thinks it’s in a container)binding_unavailable_no_marker(worst case: writer crashed before it could mark itself)no_recent_rows(no events in the last 24 hours)low_capture_rate(sub-50% match between session log files in JSON-lines format and database rows — capture is degrading)probe_disabled(the escape hatch is on — informational, not a failure)
The lesson is simple and expensive: silent degradation is the worst failure mode for a memory system. Build the marker before you build the writer. We didn’t, and a 7-day soak window passed before we noticed zero rows in the events table.
What we’d change
With the four layers in place, a few things stand out in hindsight that we’d build differently from day one.
The taxonomy was a retrofit, not a starting point. Our first index let people append anything. By the time we hit 18KB of always-loaded content, the per-session token cost was material. Six-class governance came in painfully, with bulk reclassification. Build the gate first.
The IS_DOCKER trap cost us a debugging weekend. An environment variable inherited from a container shell into a host shell caused the writer to no-op silently. It’s the canonical example of “instrumentation that breaks because of a flag you forgot to unset.” If you have a host/container split, write an explicit boundary check.
ANN parameter tuning is overrated for sub-100k corpora. We never touched the HNSW (Hierarchical Navigable Small World — the graph structure backing most modern ANN libraries) knobs. Recall stays comfortably above 0.95. Spend that engineering time on better re-ranking instead.
BM25 Phase-2 helps less than expected. Default off. Opt-in via env var. It hurts the bulk case (lesson recall) and helps a narrow case (factoid lookup) that the agent rarely hits.
Capture-rate monitoring should have been day one. We measure it now: count session JSONL files, count event rows, alert below 50% match. It’s a leading indicator for every silent-failure pathology we’ve seen.
Closing — agent harnesses are systems, not chatbots
Memory governance, class-aware retrieval, and a priming hook are plumbing. Invisible when working. But it’s what separates an agent that gets better over time from one that’s groundhog-day every Monday morning.
The pattern is portable. Any harness with a way to inject context, run hooks, and call tools can adopt this architecture. The specific stack — @ruvector/core for ANN, all-MiniLM-L6-v2 for embeddings, @modelcontextprotocol/sdk for tool exposure, better-sqlite3 for telemetry — is one valid combination. Pinecone with OpenAI embeddings and a homegrown ranker would work. So would ruflo (formerly claude-flow) sitting on top, orchestrating multi-agent swarms that consume the same memory layer — multi-agent persistence is only credible when the underlying memory is principled.
What’s not portable is the governance discipline. The taxonomy works because someone tells the agent (and the team) what not to remember. Without that, every memory system silts up.
If you’ve built something similar — or different — I’d genuinely like to compare notes. The patterns here are emergent, not finished. The next layer, in our heads at least, is active forgetting: a periodic pass that re-classifies stale entries, demotes them, or evicts. That’s the post for next quarter.
If you’re running an agent harness and want to talk shop on memory architecture, leave a comment or reach out. We’re particularly interested in approaches that handle multi-tenant memory (one harness, many users, shared lessons).